Feature steering and control vectors
This experiment begins with a simple question: how much semantic structure is contained in a frozen visual embedding space?
That question led me to build LatentLens, a very small research repo around controllable retrieval. The setup is intentionally lightweight. Just a pretrained vision backbone, a binary attribute dataset, a linear probe, and one geometric intervention in embedding space.
TL;DR
If a concept is encoded linearly enough in a frozen embedding space, then a linear probe can do more than classify it: its weight vector can also be used as a control direction. In LatentLens, pushing a query along an Eyeglasses direction in DINOv2 space gradually shifts nearest-neighbor retrieval toward images of people wearing glasses. It is a small experiment, but it suggests that frozen representation spaces may already be editable enough for attribute-level control in search.
The idea
Take a frozen image encoder such as DINOv2. Use it to embed images from a dataset with attribute labels. In my case I used CelebA-attrs-160k, which includes both images from celebrities and a set of fixed binary attributes describing each image.
Then train a linear probe on top of those frozen embeddings to classify a given binary attribute:
where z is the image embedding and w is the learned probe weight vector.
The key move is to stop thinking of w as just a classifier parameter and start treating it as a semantic direction. If the probe can reliably separate images with and without eyeglasses, then its weight vector is telling us something about where that concept lives in representation space.
Once we normalize the direction,
we can edit a query embedding by adding some amount of that direction:
and then run nearest-neighbor retrieval with the edited query instead of the original one.
That is the whole experiment.
Why it’s cool
I like this setup because it tests something very concrete. If a concept is linearly accessible in a frozen embedding space, can we also use that linear direction to control retrieval?
If the answer is yes, that means we may be able to do things like:
- Bias retrieval toward a target attribute without retraining the backbone.
- Turn semantic probes into reusable retrieval controls.
- Study what concepts are approximately linear in representation space.
- Build intuition for simple, interpretable interventions before reaching for heavier methods.
I find that appealing. There is something satisfying about getting useful behavior out of geometry alone.
There is an important caveat, though. This only works if the embeddings are good enough that the concept we care about is encoded in a roughly linear way. In practice, that means a simple linear layer should be able to separate the concept with reasonably high accuracy, or equivalently, a hyperplane should exist that cleanly divides positive and negative examples in the embedding space. If that linear separability is not there, then the probe weight is much less trustworthy as a semantic direction and the steering effect will likely be weak, unstable, or just wrong.
The experiment
The current repo focuses on one clean example: steering a query toward the Eyeglasses attribute.
I first build a balanced dataset of positive and negative examples for that attribute. Then I train a linear probe on top of frozen DINOv2 embeddings. The repo treats probe quality as a sanity check: if the probe cannot classify the attribute well enough, its direction is probably not trustworthy as a control vector. That is really the central assumption behind the whole method: the concept has to be linearly encoded well enough in the embedding space that a hyperplane can separate it.
After that, I take a query image without glasses, embed it, and move it along the learned eyeglasses direction using different values of alpha.
Finally, I retrieve the nearest neighbors from the full embedding bank and inspect how the returned images change.
Results
This is where the experiment became fun.
alpha = 0
At alpha = 0, retrieval behaves as expected. We are just using the original query embedding, so the returned neighbors mostly reflect the original identity and appearance cues.

alpha = 1
At alpha = 1, the edit starts to matter. Eyeglasses begin to show up in the retrieved set, but the results still feel close to the original query.

alpha = 2
At alpha = 2, the intervention becomes much stronger. The retrieved neighbors now consistently show women with eyeglasses. The steering is no longer subtle.

alpha = 3
At alpha = 3, the attribute begins to dominate retrieval. The system becomes so focused on glasses that some of the original cues appear less important than before.

That progression is the main reason I wanted to write about this project. The effect is not random noise. It looks structured. A small linear edit creates a coherent and interpretable shift in retrieval behavior.
What is happening
My working interpretation is simple: the frozen encoder already contains a fairly usable semantic axis for Eyeglasses, and the linear probe is recovering it well enough for retrieval-time control.
This does not mean the concept is perfectly disentangled. It also does not mean the direction is pure. In fact, one of the interesting observations is that stronger steering seems to trade away some other properties of the original query. That is exactly what you would expect if the representation mixes several correlated attributes together.
So this is not magic. It is geometry with compromises.
Projection-based thinking
Another reason this repo exists is the paper Franca: Nested Matryoshka Clustering for Scalable Visual Representation Learning by Venkataramanan, Pariza, Salehi, Knobel, Gidaris, Ramzi, Bursuc, and Asano. At a high level, Franca is an open vision foundation model built around a scalable self-supervised pipeline. A big part of the paper is about learning strong visual representations with nested Matryoshka-style clustering heads, but the part that especially caught my attention was its geometric treatment of positional bias.
Franca introduces RASA, short for Removal of Absolute Spatial Attributes. The problem they target is that patch representations in ViTs can become entangled with absolute position, so some clusters fire because a patch tends to appear in a certain region of the image rather than because it carries a genuinely semantic pattern. Their solution is elegant: learn a small linear head that predicts patch coordinates from patch embeddings, use that to identify a positional subspace, and then subtract the projection of each feature onto that subspace. In other words, they try to remove the linearly predictable “where” component so the representation keeps more of the “what.”
That is obviously not the same thing as what I do in LatentLens. RASA removes a nuisance direction, whereas my experiment adds a semantic direction to steer retrieval. But both methods share the same geometric intuition: learn something linear from a frozen representation, then directly manipulate the representation space instead of retraining the whole model.
The project is conceptually inspired by that viewpoint. LatentLens does not implement RASA directly, but it borrows the same mindset:
- Learn something linear from a frozen representation.
- Interpret that linear object as structure in feature space.
- Modify retrieval behavior by editing the representation itself.
In LatentLens I use the additive version of that idea. Instead of removing a direction, I push the query along it. But both approaches come from the same underlying belief: representation spaces are worth manipulating directly.
Applications in search systems
I think this idea gets especially interesting in search systems.
Imagine a user has found a red t-shirt they like. What they actually want is not “show me more red shirts.” What they want is “show me this exact same t-shirt, but in other colors.”
That is a much more precise retrieval problem. You want to preserve most of the item identity, shape, style, and texture, while changing just one property.
In principle, a control-vector approach gives you a simple way to try that. You could train a linear probe to distinguish red from non-red items, extract the corresponding direction in embedding space, and then steer the query in the negative direction of that control vector. If the embedding space is well behaved enough, retrieval might keep the core product semantics while walking away from the color attribute.
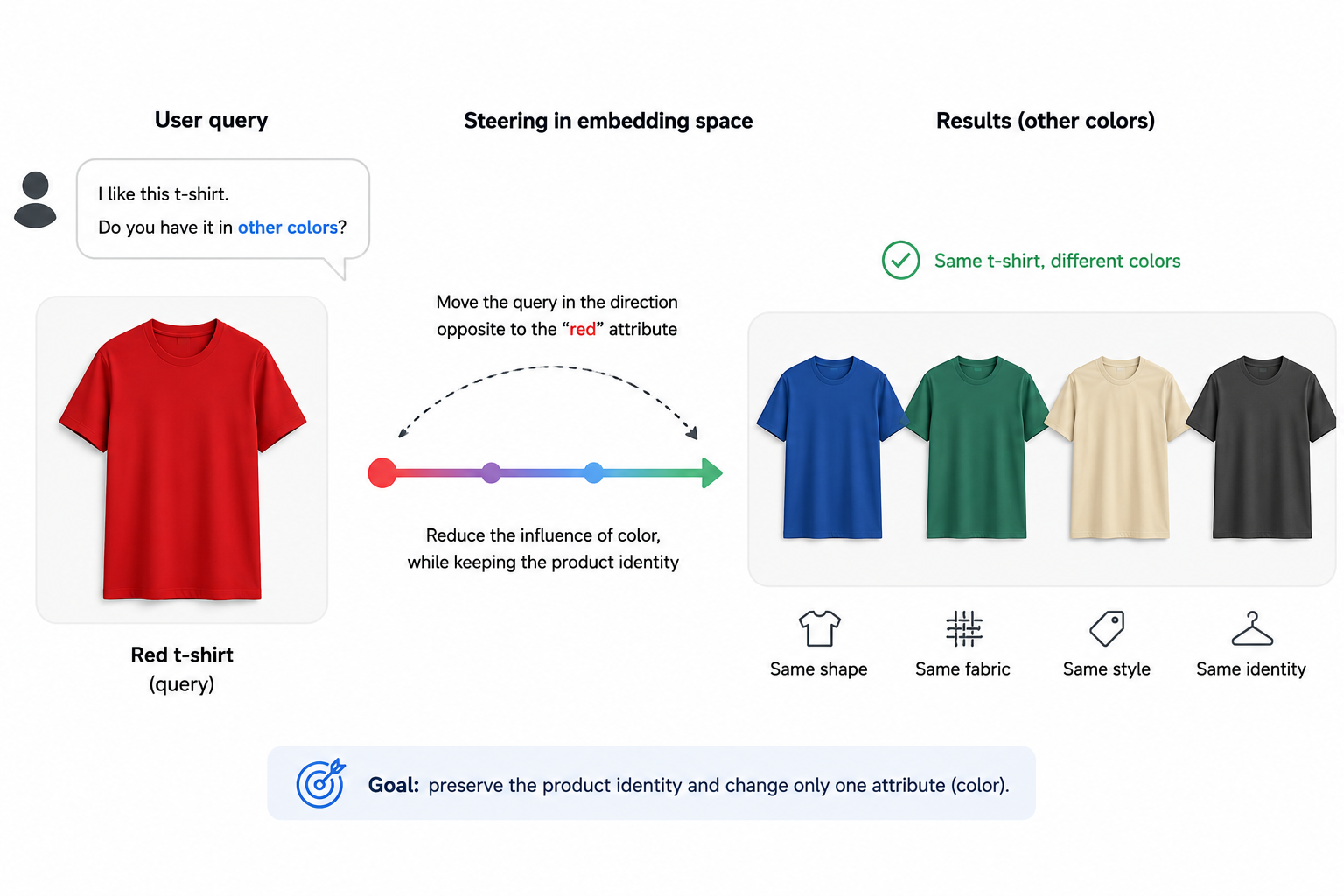
Something like this could be useful for:
- Fashion search where users want the same garment in a different color.
- Furniture or decor search where material or finish should change but shape should remain similar.
- Marketplaces where the user wants one attribute edited without losing the rest of the item identity.
Of course, this only works cleanly if the attribute direction is reasonably linear and not too entangled with the rest of the representation. That is a big “if.” But even as a lightweight retrieval-time control, it feels like a promising idea. You do not need to retrain the entire search system. You just need a frozen embedding space, some labeled examples for the attribute you care about, and a probe that recovers a useful direction.
Closing thought
If a linear probe can recover a concept, there is a good chance that concept is not just detectable but operational. We can move through it, amplify it, suppress it, and observe how behavior changes.