Steering de atributos y vectores de control
La idea detrás de este experimento parte de una pregunta bastante simple: ¿cuánta estructura semántica contiene un espacio de embeddings visuales congelado?
Esa curiosidad fue la que me llevó a crear LatentLens, un pequeño repositorio de investigación centrado en el retrieval controlable. El planteamiento es deliberadamente simple: un backbone visual preentrenado, un dataset con atributos binarios, un probe lineal y una única intervención geométrica sobre el espacio de embeddings.
TL;DR
Si un concepto está codificado de forma suficientemente lineal dentro de un espacio de embeddings congelado, un probe lineal puede hacer algo más que clasificarlo: su vector de pesos también puede utilizarse como una dirección de control. En LatentLens, desplazar una query a lo largo de una dirección asociada al atributo Eyeglasses dentro del espacio de DINOv2 hace que los vecinos más cercanos se vayan desplazando progresivamente hacia imágenes de personas con gafas.
Es un experimento pequeño, pero apunta a una idea interesante: los espacios de representación congelados podrían ser lo bastante editables como para permitir control semántico a nivel de atributo en sistemas de búsqueda.
La idea
Partimos de un encoder visual congelado como DINOv2. Lo utilizamos para obtener embeddings de imágenes pertenecientes a un dataset con etiquetas de atributos. En mi caso utilicé CelebA-attrs-160k, que incluye imágenes de celebridades junto con un conjunto de atributos binarios asociados a cada imagen.
A continuación entrenamos un probe lineal sobre esos embeddings congelados para clasificar un atributo concreto:
donde z representa el embedding de la imagen y w es el vector de pesos aprendido por el probe.
La clave está en dejar de pensar en w únicamente como un parámetro de clasificación y empezar a verlo como una dirección semántica. Si el probe es capaz de separar de forma fiable imágenes con y sin gafas, entonces su vector de pesos nos está diciendo algo sobre dónde se encuentra ese concepto dentro del espacio de representación.
Una vez normalizada la dirección,
podemos modificar un embedding de consulta sumándole una determinada cantidad de esa dirección:
y utilizar posteriormente ese embedding modificado para realizar retrieval por vecinos más cercanos.
Y eso es todo. No hay más ingredientes en el experimento.
¿Por qué me parece interesante?
Lo que me gusta de este planteamiento es que intenta responder a una pregunta muy concreta: si un concepto es linealmente accesible dentro de un espacio de embeddings congelado, ¿podemos utilizar esa misma dirección para controlar el comportamiento del retrieval?
Si la respuesta es sí, entonces podríamos plantearnos cosas como:
- Sesgar una búsqueda hacia un atributo concreto sin necesidad de reentrenar el backbone.
- Convertir probes semánticos en mecanismos reutilizables de control para retrieval.
- Estudiar qué conceptos se comportan de forma aproximadamente lineal dentro del espacio de representación.
- Desarrollar intuición sobre intervenciones simples e interpretables antes de recurrir a métodos más complejos.
Hay algo especialmente atractivo en obtener un comportamiento útil sin tocar el modelo, simplemente aprovechando la geometría del espacio latente.
Eso sí, existe una condición importante. Todo esto solo funciona si el concepto que queremos controlar está codificado de forma aproximadamente lineal dentro de los embeddings.
En la práctica, eso significa que una capa lineal sencilla debería ser capaz de separar los ejemplos positivos y negativos con una precisión razonablemente alta. Dicho de otra manera, debe existir un hiperplano capaz de dividir ambos grupos dentro del espacio de embeddings.
Si esa separabilidad lineal no existe, entonces el vector aprendido por el probe deja de ser una dirección semántica fiable y el efecto de steering probablemente será débil, inestable o simplemente incorrecto.
El experimento
La versión actual del repositorio se centra en un ejemplo bastante limpio: dirigir una query hacia el atributo Eyeglasses.
Primero construyo un conjunto equilibrado de ejemplos positivos y negativos para dicho atributo. Después entreno un probe lineal utilizando embeddings congelados de DINOv2.
La calidad del probe sirve como una comprobación rápida de que la hipótesis tiene sentido. Si el probe no es capaz de clasificar correctamente el atributo, entonces tampoco hay demasiados motivos para confiar en que la dirección aprendida vaya a funcionar como vector de control.
Al final, toda la propuesta depende de esa idea: el concepto tiene que estar representado de forma suficientemente lineal como para que un hiperplano pueda separarlo.
Una vez entrenado el probe, tomo una imagen sin gafas, obtengo su embedding y lo desplazo en la dirección aprendida utilizando distintos valores de alpha.
Por último, realizo retrieval sobre todo el banco de embeddings y observo cómo evolucionan los resultados recuperados.
Resultados
Aquí viene la parte guay del experimento.
alpha = 0
Con alpha = 0, el retrieval se comporta exactamente como cabría esperar. Estamos utilizando el embedding original de la query, por lo que los vecinos recuperados reflejan principalmente la identidad y las características visuales presentes en la imagen original.

alpha = 1
Con alpha = 1, la modificación empieza a hacerse visible. Las gafas comienzan a aparecer entre los resultados recuperados, aunque estos siguen pareciéndose bastante a la imagen original.

alpha = 2
Con alpha = 2, el efecto se vuelve mucho más evidente. Los vecinos recuperados muestran de forma consistente mujeres con gafas y el steering deja de ser algo sutil para convertirse en una tendencia clara dentro de los resultados.

alpha = 3
Con alpha = 3, el atributo empieza a dominar claramente el retrieval. El sistema da tanta importancia a la presencia de gafas que otras características de la imagen original parecen pasar a un segundo plano.

Precisamente esta progresión es la razón por la que me pareció interesante escribir sobre este proyecto. El efecto no parece ruido aleatorio ni una casualidad estadística. Se aprecia una evolución coherente y bastante interpretable.
Una modificación lineal muy simple sobre el embedding produce un cambio gradual y consistente en el comportamiento del sistema de retrieval.
¿Qué está pasando?
Mi interpretación es bastante simple: el encoder congelado ya contiene una dirección semántica razonablemente útil para Eyeglasses, y el probe lineal la recupera lo bastante bien como para permitir control durante el retrieval.
Eso no significa que el concepto esté perfectamente disentangled ni que la dirección sea pura. De hecho, una de las observaciones interesantes es que un steering más agresivo parece intercambiar algunas propiedades de la query original. Es exactamente lo que cabría esperar si la representación mezcla varios atributos correlacionados.
Así que esto no es magia. Es geometría con compromisos.
Pensar en términos de proyecciones
Otra de las razones por las que existe este repositorio es el paper Franca: Nested Matryoshka Clustering for Scalable Visual Representation Learning de Venkataramanan, Pariza, Salehi, Knobel, Gidaris, Ramzi, Bursuc y Asano.
A grandes rasgos, Franca es un vision foundation model abierto construido sobre una pipeline auto-supervisada escalable. Una parte importante del trabajo se centra en aprender representaciones visuales mediante clustering tipo Matryoshka, pero la sección que más me llamó la atención fue su tratamiento geométrico del sesgo posicional.
Franca introduce RASA (Removal of Absolute Spatial Attributes). El problema que aborda es que las representaciones de parches en los ViTs pueden acabar mezcladas con información de posición absoluta, de modo que algunos clusters se activan porque un parche suele aparecer en una región concreta de la imagen y no porque represente un patrón genuinamente semántico.
La solución es elegante: entrenar una pequeña cabeza lineal que prediga coordenadas de parche a partir de embeddings de parche, utilizarla para identificar un subespacio posicional y posteriormente restar la proyección de cada feature sobre dicho subespacio.
Dicho de otra forma, intentan eliminar la componente linealmente predecible del “dónde” para conservar más del “qué”.
Obviamente, esto no es lo mismo que hago en LatentLens. RASA elimina una dirección de nuisance, mientras que mi experimento añade una dirección semántica para dirigir el retrieval. Pero ambos enfoques comparten la misma intuición geométrica: aprender algo lineal a partir de una representación congelada y después manipular directamente el espacio de representación.
LatentLens no implementa RASA, pero comparte esa filosofía:
- Aprender algo lineal a partir de una representación congelada.
- Interpretarlo como estructura dentro del espacio de features.
- Modificar el comportamiento del sistema editando la representación.
En LatentLens utilizo la versión aditiva de esa idea. En lugar de eliminar una dirección, desplazo la query a lo largo de ella. Pero ambos enfoques parten de la misma premisa: merece la pena manipular directamente los espacios de representación.
Aplicaciones en sistemas de búsqueda
Creo que esta idea se vuelve especialmente interesante en sistemas de búsqueda.
Imagina que una persona encuentra una camiseta roja que le gusta. Lo que realmente quiere no es “enséñame más camisetas rojas”. Lo que quiere es “enséñame esta misma camiseta, pero en otros colores”.
Ese es un problema de retrieval mucho más preciso. Queremos conservar la mayor parte de la identidad del producto mientras modificamos una única propiedad.
En principio, un enfoque basado en vectores de control ofrece una forma sencilla de intentarlo. Podríamos entrenar un probe lineal para distinguir productos red de non-red, extraer la dirección correspondiente y desplazar la query en la dirección opuesta de ese vector. Si el espacio de embeddings se comporta de forma razonablemente lineal, el sistema podría conservar la semántica principal del producto mientras reduce la influencia del color.
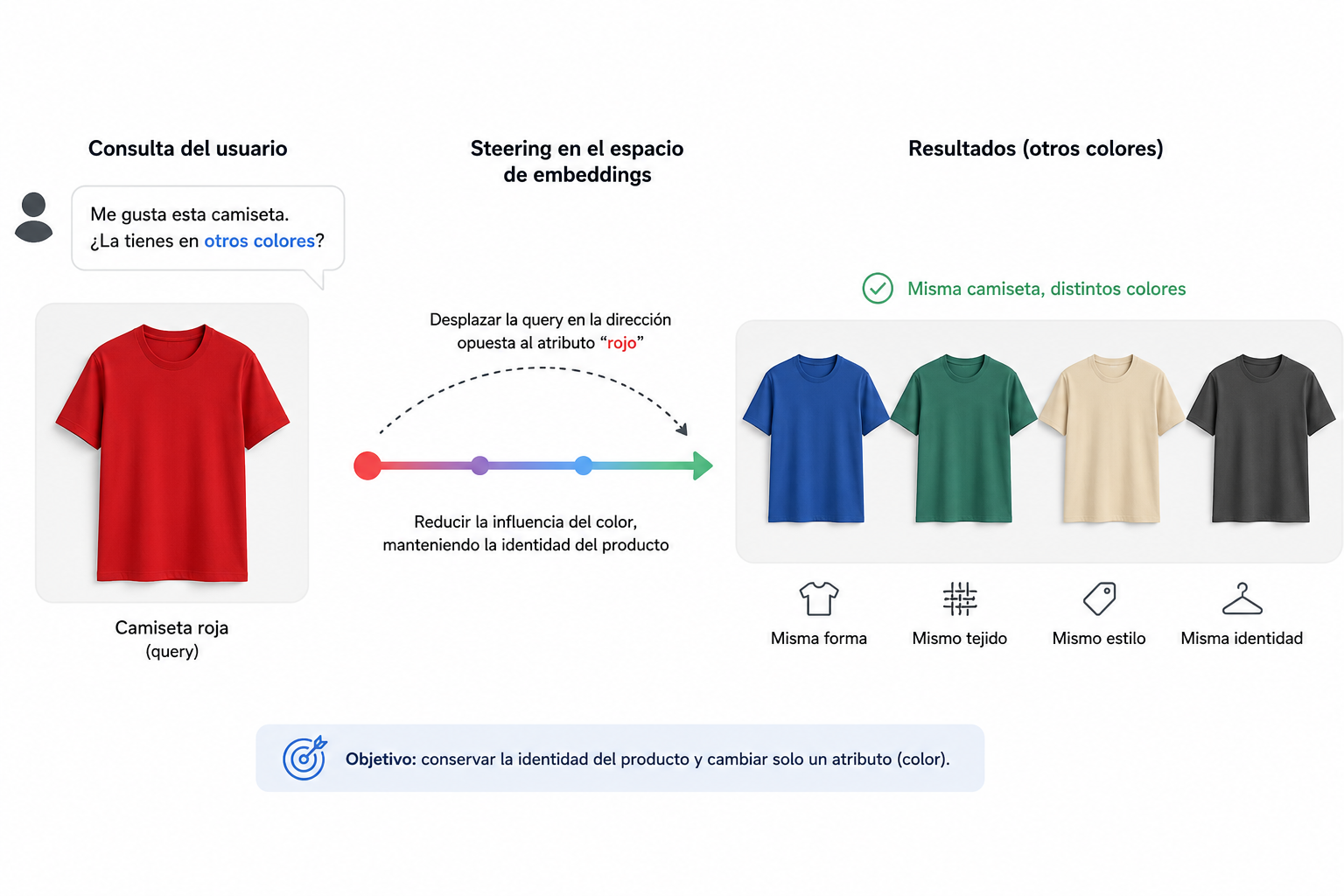
Algo así podría ser útil en búsqueda de moda, decoración o marketplaces donde queremos modificar un atributo sin perder el resto de la identidad del producto.
Por supuesto, esto solo funciona si la dirección asociada al atributo es suficientemente lineal y no está demasiado entremezclada con el resto de la representación. Es un supuesto fuerte, pero incluso como mecanismo ligero de control en tiempo de retrieval me parece una idea prometedora.
No hace falta reentrenar todo el sistema de búsqueda. Solo necesitamos:
Reflexión final
Si un probe lineal puede recuperar un concepto, es probable que ese concepto no solo pueda detectarse, sino también utilizarse. Podemos movernos a lo largo de esa dirección, amplificarla, reducirla y observar cómo cambia el comportamiento del sistema.